오토인코더 기반 네트워크 침입 탐지 방법 연구(1)
지난 발표내용이 너무 어려웠던것 같아서 조금 더 이해하기 편하도록 설명을 조금 더 자세하게 적었습니다.
1. 연구 배경 및 동향 분석
- 최근 인공지능, 빅데이터, IoT(사물인터넷) 등의 기술이 우리 일상생활 속 에서 많이 사용되면서, 그에 따라 보안에 대한 이슈도 대두되고 있습니다. 특히 최근 발생한 LG유플러스 DDoS 공격에 대한 피해를 인상 깊게 접하게 되고 네트워크 침입공격에 대한 빠른 탐지의 중요성을 느끼게 되어 이 주제를 선정하게 되었습니다. 과거에는 패턴기반의 네트워크 침입탐지를 연구했다면 AI가 대두됨에 따라 지도학습 기반의 연구들이 진행되어졌습니다. 최근에는 강화학습 또는 비지도학습을 통해 새로운 유형의 공격에 대해서도 예측하고 발견할 수 있는 모델들을 연구하는 추세입니다.

2. 연구 흐름도

1) 먼저 연구에 알맞는 데이터셋을 선정합니다.
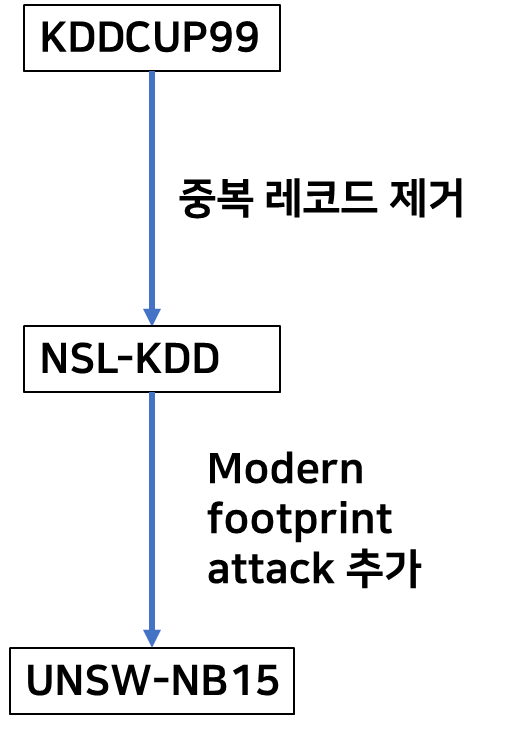
최근까지 가장 많이 사용한 데이터셋인 KDDCUP99와 NSL-KDD는 같은 내용을 담고 있지만 KDDCUP99의 중복 레코드가 많다는 단점을 보안한 데이터 셋이 NSL-KDD 데이터 셋입니다. 하지만 NSL-KDD 데이터셋도 실제 네트워크 환경의 문제를 반영하지 못했다는 한계점이 있습니다. 실제 네트워크 환경에서의 네트워크 침입에는 대표적으로 Modern Footprint attack이 있습니다. 이 공격은 실제 네트워크에 침입했지만 침입하지 않았던 것 처럼 위장을 하는 공격을 의미합니다. 이런 종류의 여러 공격들을 추가해서 만들어낸 UNSW-NB15라는 데이터셋이 실제 네트워크 환경 연구에 적합하다는 생각하에 UNSW-NB15 데이터셋을 선정하게 되었습니다.
2) 데이터 중요 특성 선택 알고리즘
중요 특성 선택 알고리즘에는 대표적으로 Filter method, Wrapper Method, Embedded Method로 나뉘어 집니다. 저희는 Embedded Method를 사용하여 중요 특성 선택을 하려고합니다. Embedded Method의 경우 직접 모델에 학습을 시키면서 특성의 중요도를 측정하는 방식을 의미합니다.

그 중에서도 Permutation Importance 알고리즘을 사용합니다. Permutation Importance 알고리즘이란 랜덤하게 특성을 선택하여 해당 특성의 값들을 shuffle하여 다른 특성들간의 상관관계를 끊어내는 형식으로 이루어집니다. 간단하게 설명해보면 다음과 같습니다.
변수 p라는게 랜덤하게 선택되었다고 한다면 변수 p의 값들이 모두 섞이게 됩니다. 그 후 변수 p가 shuffle된 데이터 셋을 모델에 학습시켜서 성능이 저하된다면 변수 p의 중요도가 높다고 책정되게 되는 형식입니다. 왜냐하면 변수p가 중요한 특성이여서 이 변수의 값들을 섞게 되면 실제 예측이 어려워져서 성능이 저하되었다고 판단하기 때문입니다. 반대로 성능이 향상되면 변수 p의 중요도가 낮아지게 측정되어서 이러한 방식을 permutation값 만큼 동작시켜서 특성의 중요도를 판단하게 됩니다.
3) 모델 선정
저희는 비지도 학습 모델을 사용하여 새로운 유형의 공격도 탐지할 수 있도록 하는 것이 목표입니다. 더 나아가서 기존에 있던 모델들 보다 조금 더 빠른 속도로 탐지해보는게 목표이기 때문에 학습 속도 및 테스트 속도를 줄이기 위해서 feature selction방식과 autoencoder 모델을 사용하게 되었습니다.
물론 AutoEncoder가 다른 비지도 학습 모델이나 지도 학습 모델보다 빠르다는 절대적인 지표는 존재하지 않지만 모델의 원리 자체가 Encoder를 통해서 특성을 압축하는 형식으로 작동하고 기본적인 모델 자체가 hidden layer층이 적은 모델이어서 CNN 모델이나 복잡한 연산이 필요한 모델보다는 빠른 속도의 탐지가 가능할 것으로 예상하고 있습니다.
또한 이상탐지 비지도 모델로는 PCA, OCSVM, AutoEncoder가 대표적으로 존재합니다. 하지만 PCA는 비선형 분류에 부적합 하고(물론 kernal-pca의 경우는 비선형이 가능하지만 10번 출처자료의 논문에 의하면 오토인코더가 더 높은 성능을 보이고 있습니다.) OCSVM의 경우는 고차원 데이터에 대한 성능이 감소한다는 문제점을 가지고 있어서 이러한 문제점을 모두 해결 가능한 AutoEncoder모델을 선정했습니다.


3. 개선점 및 추가사항
- 먼저 UNSW-NB15 데이터셋의 데이터셋을 분석해야 합니다. 어떤 특성들이 있고 특성들간의 상관관계를 알아야 PI알고리즘을 적용할때 도움이 될 것으로 예상되어집니다.
- 어떤 AutoEncoder 모델이 적합할지에 대한 테스트가 필요해 보입니다.
- 기존보다 더 빠르게 탐색한다는 점을 보이기 위한 정확한 성능 지표 기준이 필요합니다.
- PI알고리즘에 대한 정확한 코드적인 분석이 필요해보입니다.
4. 출처 및 참고 문헌
[1] https://www.kaggle.com/code/harangdev/feature-selection/notebook
[2] https://wooono.tistory.com/249
[3] 김선영, 오창석, 패턴매칭 기법을 이용한 DDoS 공격 탐지 기법, 한국콘텐츠학회 [2005]
[4] 조강홍, 이도훈, 시계열 모델 기반 트래픽 이상탐지 기법에 대한 연구, 한국통신학회논문지 '08-05 Vol. 33 No.5 [2008]
[5] https://ieeexplore.ieee.org/document/7348942
[6] 민병준, 유지훈, 김상수 ,오토인코더 기반의 단일 클래스 이상 탐지 모델을 통한 네트워크 침입 탐지), Journal of Internet Computing and Services, v.22 no.1 [2021]
[7] https://hwi-doc.tistory.com/entry/Feature-selection-feature-importance-vs-permutation-importance
[8] Dor Bank, Noam Koenigstein, Raja Giryes, Autoencoders [2021]
[9] https://research.unsw.edu.au/projects/unsw-nb15-dataset
[10] https://scikit-learn.org/stable/auto_examples/ensemble/plot_forest_importances.html
[11] https://blog.naver.com/pentamkt/222084745829
[12] P Li, Y Pei, J Li, A comprehensive survey on design and application of autoencoder in deep learning [2023]
[13] Mayu Sakurada, Takehisa Yairi, Anomaly Detection Using Autoencoders with Nonlinear Dimensionality Reduction [2014]
[14] 강구홍, 비지도학습 오토 엔코더를 활용한 네트워크 이상 검출 기술 [2020]
[15] 유재학, 박준상, SVM을 이용한 SNMP MIB에서의 트래픽 폭주 공격 탐지[2008]
긴 글 읽어 주셔서 감사합니다.